Kafka 和 Pulsar 的 Compaction 实现
本文主要对 Kafka 和 Pulsar 的 Log Compaction 原理进行介绍,并以我的理解进行简单的对比说明。
在 Kafka 和 Pulsar 中,都具备 Log Campaction(日志挤压)的能力,Compaction 不同于 Log Compression(日志压缩),Compaction 是指将 Topic 历史日志中相同 Key 的消息只保留最新的一条,而 Compression 是指消息维度利用各种压缩算法(如:gzip、lz4、zstd等)减小消息大小但不改变消息内容。Compaction 的使用场景的特点:一是消息有 key,二是相同 key 的消息只关心最新的内容,例如:记录每支股票价格变动的 Topic,股票名称设置为 key,股票价格设置为 value,一般只关心股票的最新价格。在这种场景下,配置 Compaction 可以让 Topic 存储的数据更少,从而在需要全量读取 Topic 内容时速度更快。
Kafka Log Compaction
本文介绍基于 Kafka 2.8,并且忽略了幂等消息、事务消息的相关处理逻辑,如有兴趣,可以自行阅读源码了解。
在 Kafka 中,Topic 配置 cleanup.policy用来控制 Topic 的数据清理策略,该配置的可选值有两个:一个是delete,表示 Topic 中数据超过保留时间或保留大小限制时,直接删除最旧的数据;另一个是compact,表示对于 Topic 中的旧数据(非 Active Segment 中的数据)执行挤压,一定范围内,对于 key 相同(没有 key 的消息会被删除)的消息,只保留最新的一条。对于每个 Topic 可以选择一种清理策略进行配置,也可以同时配置两种策略。本文介绍的是 compact这个策略,在 Kafka 使用过程中,用来存放 commit offset 信息的的内部 Topic:__consumer_offsets 会被配置为该策略,普通 Topic 一般很少使用。
实现原理
对于一台 Kafka Broker, Log Compaction 的主要流程如下:
- 创建 LogCleaner,启动配置指定数量的 CleanerThread,负责该 Broker 的 Log Compaction。
- 每个 CleanerThread 循环执行日志清理工作,循环过程如下:
- 寻找一个待清理的 TopicPartition。
- 遍历该TopicPartition 中所有待清理的 Segment,构造 OffsetMap 记录每个 key 最新的 offset 及对应的消息时间。
- 对该TopicPartition 中所有待清理的 Segment 进行分组,保证每组 Segment 的 Log 文件总大小和 Index 文件总大小不会超过 LogConfig 允许的范围并且每组 Segment 的 offset 极差不会超过
Int.MaxValue(Kafka 中 Segment 内的相对 offset 为整型,这个检查是为了避免相对 offset 溢出)。 - 将 Segment 按照分好的组进行清理,每一组 Segment 聚合为一个新的 Segment。每组 Segment 的清理过程为:创建一个新的 Segment,然后根据 OffsetMap 中记录的信息选择需要保留的消息,存入新 Segment,最后使用新 Segment 覆盖这一组旧 Segment。
- 对于所有已经执行完成 Compaction 流程并且
cleanup.policy配置包含compact策略的 Log 进行删除,本次删除不是前面用一个新 Segment 替换一组旧 Segment 中的删除,而是调用Log.deleteOldSegments。该方法会删除LogStartOffset之前的所有 Segment,如果cleanup.policy配置同时还包含delete策略,也会删除超过保留时间或保留大小限制的 Segment。
详细说明
下面以Q&A的方式介绍日志清理的细节和逻辑:
多个 CleanerThread 是如何保证 Compaction 过程线程安全的?
Kafka 中 Log Compaction 的实现主要是LogCleaner和LogCleanerManager两个类,LogCleaner是 Compaction 工作的主类,负责整体的工作流程,LogCleanerManager负责 Compaction 状态机的管理。所有状态如下:
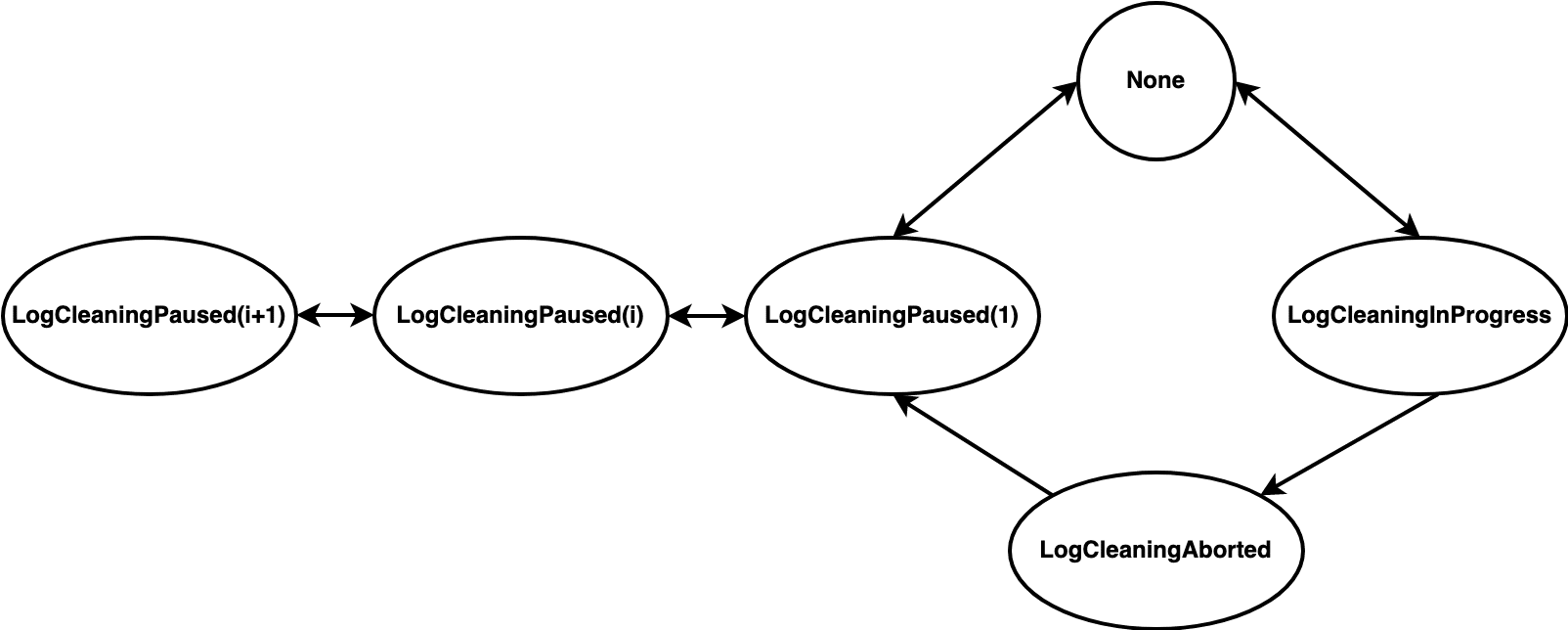
None:TopicPartition 未清理状态。LogCleaningInProgress:清理正在进行中,当 TopicPartition 被选中为待清理 Log 时会变为该状态。LogCleaningAborted:清理中止,这是一个从LogCleaningInProgress到LogCleaningPaused(1)的中间状态,在外部发生 truncate、坏盘等情况时需要放弃现在正在的清理操作, 终止后该 TopicPartition 会标记为LogCleaningAborted。LogCleaningPaused(i):清理暂停,i 的初始值为1,这是一个重入的状态,即:如果当前状态是LogCleaningPaused(i),再次暂停该 TopicPartition 的话,状态会变为LogCleaningPaused(i+1),从暂停状态恢复的话,状态会变为LogCleaningPaused(i-1)(i-1=0 时直接变为None状态)。会触发状态变为LogCleaningPaused(i)的情况如下(下面的“暂停”和“暂停恢复”分别代表 i + 1 和 i - 1):- Topic 配置
cleanup.policy不包含compact:暂停 - 外部发生 truncate、坏盘等情况时该 TopicPartition 状态为
None或LogCleaningPaused(i):暂停 - 本轮清理完成且该 TopicPartition 状态为
LogCleaningAborted:暂停 - 触发暂停的操作完成:暂停恢复
- Topic 配置
我理解中止状态和暂停状态的区别是:是否可以在本轮清理中恢复。在外部发生 truncate、坏盘等情况时,如果一个 TopicPartition 没有处于清理过程中,可以标记为暂停,在触发暂停的情况结束后,恢复清理流程就会重新执行清理流程。但是如果该 TopicPartition 处于清理过程中,则必须标记为终止,在触发暂停的情况结束后,即使本轮清理没结束,也必须要先标记为暂停,在下轮操作进行清理。这是因为如果已经在清理过程中了,本轮清理会有一些中间态的信息,不容易从中间态进行恢复。
对于每个 CleanerThread,每次都会通过LogCleanerManager.grabFilthiestCompactedLog方法来搜索状态为None并且需要被清理的 TopicPartition 进行清理。LogCleanerManager中的所有状态变更都会加锁,保证状态机是线程安全的,多个 CleanerThread 通过该状态机保证了所有 TopicPartition 的 Compaction 过程是线程安全的。
如何决定哪些 TopicPartition 应该被清理(LogCleanerManager.grabFilthiestCompactedLog的详细流程)?
可以清理的 TopicPartition 限制条件有以下几个:
Topic 配置
cleanup.policy包含compact。TopicPartition 的状态为空:说明没有其他 CleanerThread 操作该 TopicPartition。
该 TopicPartition 是可以清理的:因为坏盘等问题某些 TopicPartition 会被标记为不可清理,需要跳过。
不需要延迟清理:消息在日志中必须存在
"max.compaction.lag.ms"指定的时间后才能被删除(详情可参考KIP-354),只有第一个未压缩 Segment 的估计最早消息时间戳早于"max.compaction.lag.ms"才会可以进行 Compaction。需要被清理的消息总大小大于0:从 LogStartOffset 或 CleanCheckPoint 开始到满足
"max.compaction.lag.ms"配置要求的 offset 之间的消息总大小满足清理频率满足要求:有关清理频率的配置可以直接看下面源码 Doc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public static final String MIN_COMPACTION_LAG_MS_CONFIG = "min.compaction.lag.ms";
public static final String MIN_COMPACTION_LAG_MS_DOC = "The minimum time a message will remain " +
"uncompacted in the log. Only applicable for logs that are being compacted.";
public static final String MAX_COMPACTION_LAG_MS_CONFIG = "max.compaction.lag.ms";
public static final String MAX_COMPACTION_LAG_MS_DOC = "The maximum time a message will remain " +
"ineligible for compaction in the log. Only applicable for logs that are being compacted.";
public static final String MIN_CLEANABLE_DIRTY_RATIO_CONFIG = "min.cleanable.dirty.ratio";
public static final String MIN_CLEANABLE_DIRTY_RATIO_DOC = "This configuration controls how frequently " +
"the log compactor will attempt to clean the log (assuming <a href=\"#compaction\">log " +
"compaction</a> is enabled). By default we will avoid cleaning a log where more than " +
"50% of the log has been compacted. This ratio bounds the maximum space wasted in " +
"the log by duplicates (at 50% at most 50% of the log could be duplicates). A " +
"higher ratio will mean fewer, more efficient cleanings but will mean more wasted " +
"space in the log. If the " + MAX_COMPACTION_LAG_MS_CONFIG + " or the " + MIN_COMPACTION_LAG_MS_CONFIG +
" configurations are also specified, then the log compactor considers the log to be eligible for compaction " +
"as soon as either: (i) the dirty ratio threshold has been met and the log has had dirty (uncompacted) " +
"records for at least the " + MIN_COMPACTION_LAG_MS_CONFIG + " duration, or (ii) if the log has had " +
"dirty (uncompacted) records for at most the " + MAX_COMPACTION_LAG_MS_CONFIG + " period.";
OffsetMap 的实现原理
OffsetMap 的实现类是SkimpyOffsetsMap,用来存储 message key 和 offset 的映射关系,用来保存相同 key 下最新消息的 Offset。此处不介绍该类的详细实现(感兴趣自行阅读源码),只列举其特点:
- 创建时需要指定两个参数,一个是 memory,用来指定存储 offset 的 ByteBuffer 大小,另一个是 hashAlgorithm,用来确定计算 key hash 时使用的哈希算法。
- 只允许增加,不允许删除。
- 只在 ByteBuffer 中存储需要记录的 offset,每次 put/get 都是先对 key hash 确定 position,然后直接修改/读取 ByteBuffer 中的内容。
我理解该实现的主要优点是避免存储 message key,减少内存消耗。
如何从一组旧的 Segment 中过滤出需要保留的消息以及过滤策略是怎样的?
过滤消息的流程是,先将旧 Segment 中的消息读入MemoryRecords,然后使用MemoryRecords.filterTo方法进行过滤,该方法支持使用自定义实现的 RecordFilter 过滤消息。
消息过滤的策略(实际会有事务消息的处理)是:过滤掉相同 key 中非最新 offset 的消息以及满足删除条件的墓碑消息(key 不为 null 但是 value 为 null)。墓碑消息的删除条件是指,该墓碑消息所在的 Segment 最后修改时间距离最新 Segment 的最后修改时间超过delete.retention.ms配置的时间。
如果 Compaction 过程中 Broker 崩溃,重启后如何恢复?
宕机恢复的考虑只发生在用新 Segment(文件名后缀是.cleaned) 替换旧 Segment 的过程中,其他阶段发生宕机的话,恢复后重新执行 Compaction 流程即可。
Segment 替换操作使用replaceSegments方法(源码如下)完成,替换流程是:
- 将新 Segment 的文件名后缀从
.cleaned改为.swap - 删除旧 Segment:删除过程是先将同步将文件后缀改为
.deleted,然后进行异步删除 - 去掉新 Segment 的文件名后缀,流程结束
下面是对于所有可能的阶段 Broker 崩溃后的恢复逻辑:
- 步骤1之前:如果此时 broker 崩溃,则清理和交换操作将中止,并且在
loadSegments()中恢复时删除.cleaned文件。 - 步骤1执行过程中崩溃:新 Segment 重命名为
.swap。如果代理在所有 Segment 重命名为.swap之前崩溃,则清理和交换操作将中止.cleaned以及.swap文件在loadSegments()恢复时被删除。.cleaned重命名为.swap是按照文件按偏移量的降序进行的,恢复时,所有偏移量大于最小偏移量.clean文件的.swap文件都将被删除。 - 步骤1完成后崩溃:如果在所有新 Segment 重命名为
.swap后代理崩溃,则操作完成,剩余操作流程会在 Broker 恢复时继续执行。 - 步骤2执行过程中崩溃:旧 Segment 文件被重命名为
.deleted并安排了异步删除。如果 Broker 崩溃,任何留下的.deleted文件都会在loadSegments()恢复时被删除,然后调用replaceSegments()以完成替换,其中新 Segment 从.swap文件重新创建,旧 Segment 包含在崩溃前未重命名的 Segment。 - 步骤3完成后崩溃:此时可能存在未被异步删除完成的旧 Segment,任何可能留下的
.deleted文件都会在loadSegments()恢复时被删除
1 | private[log] def replaceSegments(newSegments: Seq[LogSegment], oldSegments: Seq[LogSegment], isRecoveredSwapFile: Boolean = false): Unit = { |
Pulsar Compaction
Pulsar 官方文档中关于 Compaction 的介绍也比较详细,具体可以参考:
- https://pulsar.apache.org/docs/zh-CN/next/concepts-topic-compaction/#compaction
- https://pulsar.apache.org/docs/zh-CN/next/cookbooks-compaction/
- https://github.com/ivankelly/incubator-pulsar-wiki/blob/pip-9/PIP-9:-Topic-Compaction.md
在 Pulsar 中,Topic Compaction 与 NonCompaction 两个状态不是相互对立的,Compaction 是通过类似于创建一个Subscription 来消费现有 Topic 的消息,经过 Compaction 处理后,写入新的 Ledger 存储,在 Consumer 消费时,可以通过配置选择读取 Compacted 数据还是 NonCompacted 数据。注意:Compact 只能对 persistent topic 执行。
触发条件
Pulsar 中触发 Topic Compaction 的方式有两种:
- 配置
CompactionThreshold:如前面所说,Compaction 过程相当于建立一个 Subscription 来消费原来 Topic 中的数据写入新的 Ledger,Broker 会周期性检查所有 Persistent Topic,如果CompactionThreshold配置不为0并且这个 Subscription 的消息积压超过了配置的阈值,就会自动触发 Compaction。这个配置的粒度可以是 topic、broker、namespace,最终根据优先级(topic > broker > namespace)确定最终配置值。 - 外部触发 Topic Compaction:除自动触发 Compaction 外,也可以通过 CLI 工具触发,一种是 AdminCli,需要调用 broker 提供的 RestAPI,另一种是使用专用工具类,不经过 RestAPI 直接指定。
1 | bin/pulsar-admin topics compact persistent://my-tenant/my-namespace/my-topic # AdminCli |
实现原理
实现原理总体可以分为 Compaction 的处理过程和 Consumer 读取 Compacted 数据两个部分。
Compaction 处理
触发 Compaction 的统一入口是Compactor.compact(String topic)方法,Compactor是一个抽象类,目前的实现只有TwoPhaseCompactor一种,下面介绍的是TwoPhaseCompactor的实现逻辑。顾名思义,Compaction 过程分为两个阶段,遍历两次 Topic 内容,第一次遍历用来获取每个 key 中最新的 MessageId(相当于 Kafka 中的 offset),第二次遍历根据第一次遍历取得的结果,只将每个 key 的最新消息写入新的 Ledger 中。
读取 Compacted 数据
如果 Consumer 希望读取 Compacted 数据,需要在初始化时制定相关配置。
1 | Consumer<byte[]> compactedTopicConsumer = client.newConsumer() |
Broker 在收到 Consumer 的请求后,会先获取到 Topic 对应的 cursor 信息,然后从 cursor 信息中找到 Compacted 数据对应的 LedgerId,然后进行对应数据的读取。
Compacted Leger 信息如何传递给 Consumer?
如前文所说,在TwoPhaseCompactor处理过程中,实际是创建了一个 Subscription 来读取原来的数据。在读取数据完成进行 Ack 时,使用的接口是RawReader.acknowledgeCumulativeAsync(MessageId messageId, Map<String, Long> properties),该接口可以在 Ack 的同时给 Broker 返回一些该 Subscription 的元信息,Broker 会将收到的元信息记录在 cursor 信息中。所以,TwoPhaseCompactor通过这一能力,将创建的用来存储 Compacted 数据的 LedgerId 记录在了 cursor 信息中,方便 Consumer 读取时使用。
总结思考
Kafka 和 Pulsar 中实现 Compaction 的目的是为了在特定的场景下减少 Topic 的数据量,加快获取 Topic 中全部数据的速度,而不是希望实现类似 KV 存储的能力。之所以这样说,是因为:
- Kafka 和 Pulsar 都没有保证最新数据的 Compaction:对于 Kafka 来说,Log Compaction 只会操作 ActiveSegment 之前的数据;对于 Pulsar 来说,Compaction 是一个周期性执行的工作,每次 Compaction 开始之前,都会先读取当前 Topic 中最后一个 MessageId 作为本轮 Compaction 的终点,因此只要有 Producer 在向 Topic 生产数据。就肯定不能保证所有数据都被 Compacted。
- Kafka 和 Pulsar 的 Compaction 都是一定范围内的,不是全局的:Kafka 和 Pulsar 的 Compaction 都是以一种类似于滑动窗口的过程进行,“key 相同的情况下只保留最新的消息”针对的是一轮 Compaction 内,如果两轮 Compaction 中有相同 key 的消息,是没有办法合并的。
对比 Kafka 和 Pulsar 两者的实现来看,最主要的区别就是是否保留 Compaction 前的数据。相较于 Kafka 的实现,Pulsar 这种形式一方面整体逻辑更为简单,不需要考虑各种文件替换过程中的崩溃恢复逻辑,另一方面也可以给 Consumer 更多选择的空间,但是这样也会带来一定的存储成本。两者的实现架构是不同的,如果想要 Kafka 也像 Pulsar 一样保留两份数据,由于 Kafka 的存储副本机制是自己的管理的,可能需要比现在更为复杂的实现才能够搞定,而不能像 Pulsar 一样直接通过切换 LedgerId 来选择数据就可以了。