1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
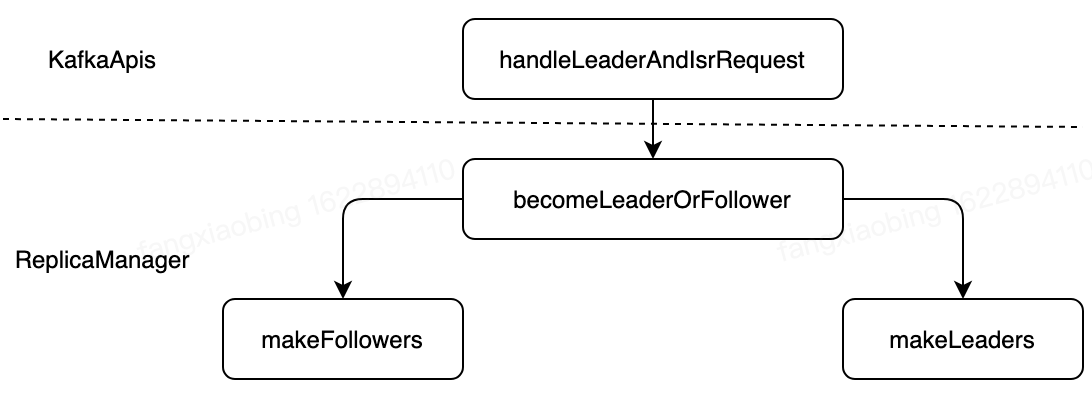
| def becomeLeaderOrFollower(correlationId: Int,leaderAndISRRequest: LeaderAndIsrRequest,
metadataCache: MetadataCache,
onLeadershipChange: (Iterable[Partition], Iterable[Partition]) => Unit): BecomeLeaderOrFollowerResult = {
leaderAndISRRequest.partitionStates.asScala.foreach { case (topicPartition, stateInfo) =>
stateChangeLogger.trace("Broker %d received LeaderAndIsr request %s correlation id %d from controller %d epoch %d for partition [%s,%d]"
.format(localBrokerId, stateInfo, correlationId,
leaderAndISRRequest.controllerId, leaderAndISRRequest.controllerEpoch, topicPartition.topic, topicPartition.partition))
}
replicaStateChangeLock synchronized {
val responseMap = new mutable.HashMap[TopicPartition, Short]
if (leaderAndISRRequest.controllerEpoch < controllerEpoch) {
stateChangeLogger.warn(("Broker %d ignoring LeaderAndIsr request from controller %d with correlation id %d since " +
"its controller epoch %d is old. Latest known controller epoch is %d").format(localBrokerId, leaderAndISRRequest.controllerId,
correlationId, leaderAndISRRequest.controllerEpoch, controllerEpoch))
BecomeLeaderOrFollowerResult(responseMap, Errors.STALE_CONTROLLER_EPOCH.code)
} else {
val controllerId = leaderAndISRRequest.controllerId
controllerEpoch = leaderAndISRRequest.controllerEpoch
val partitionState = new mutable.HashMap[Partition, PartitionState]()
leaderAndISRRequest.partitionStates.asScala.foreach { case (topicPartition, stateInfo) =>
val partition = getOrCreatePartition(topicPartition)
val partitionLeaderEpoch = partition.getLeaderEpoch
if (partitionLeaderEpoch < stateInfo.leaderEpoch) {
if(stateInfo.replicas.contains(localBrokerId))
partitionState.put(partition, stateInfo)
else {
stateChangeLogger.warn(("Broker %d ignoring LeaderAndIsr request from controller %d with correlation id %d " +
"epoch %d for partition [%s,%d] as itself is not in assigned replica list %s")
.format(localBrokerId, controllerId, correlationId, leaderAndISRRequest.controllerEpoch,
topicPartition.topic, topicPartition.partition, stateInfo.replicas.asScala.mkString(",")))
responseMap.put(topicPartition, Errors.UNKNOWN_TOPIC_OR_PARTITION.code)
}
} else {
stateChangeLogger.warn(("Broker %d ignoring LeaderAndIsr request from controller %d with correlation id %d " +
"epoch %d for partition [%s,%d] since its associated leader epoch %d is not higher than the current leader epoch %d")
.format(localBrokerId, controllerId, correlationId, leaderAndISRRequest.controllerEpoch,
topicPartition.topic, topicPartition.partition, stateInfo.leaderEpoch, partitionLeaderEpoch))
responseMap.put(topicPartition, Errors.STALE_CONTROLLER_EPOCH.code)
}
}
val partitionsTobeLeader = partitionState.filter { case (_, stateInfo) =>
stateInfo.leader == localBrokerId
}
val partitionsToBeFollower = partitionState -- partitionsTobeLeader.keys
val partitionsBecomeLeader = if (partitionsTobeLeader.nonEmpty)
makeLeaders(controllerId, controllerEpoch, partitionsTobeLeader, correlationId, responseMap)
else
Set.empty[Partition]
val partitionsBecomeFollower = if (partitionsToBeFollower.nonEmpty)
makeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, correlationId, responseMap, metadataCache)
else
Set.empty[Partition]
if (!hwThreadInitialized) {
startHighWaterMarksCheckPointThread()
hwThreadInitialized = true
}
replicaFetcherManager.shutdownIdleFetcherThreads()
onLeadershipChange(partitionsBecomeLeader, partitionsBecomeFollower)
BecomeLeaderOrFollowerResult(responseMap, Errors.NONE.code)
}
}
}
|